Once upon a time there was Ethernet. Every half decade or so, the industry got together and worked out a faster version. Sometimes they didn’t totally agree, but a standard emerged at 10x the speed of the previous version. Throw all that out the window: Faster Ethernet is coming, and it’s going to be weird!
Although it looks like a simple network Channel, Ethernet is anything but. Ever since the development of “Fast Ethernet” (that’s 100 Mb Ethernet to you and me), the IEEE has considered using multi-lane communications in various Ethernet standards. Today’s common 1000BASE-T standard multiplexes 125 Mbps signals, and 10GBASE-CX4 uses four separate 3.125 Gbps lanes.
Faster Than 10 Gb Ethernet in the Datacenter
This multi-lane weirdness is really amped up when we look beyond 10 Gb Ethernet! Essentially, there are two popular lane or channel rates:
- 10.3125 Gbps used alone (as 10 Gb Ethernet) or in 40 Gb or 100 Gb Ethernet (and 1G and NBASE-T, which I’ll get to in a moment). Intel and Cisco seem to like this set of speeds.
- 25.78125 Gbps is also used alone (as 25 Gb Ethernet) or in 50 Gb or 100 Gb Ethernet. This is popular with NIC and switching vendors like QLogic and Avago (via acquisitions of Broadcom and Emulex).
Already, the datacenter server market, looking beyond 10 Gb Ethernet, is facing a choice between the Intel-led 40/100 roadmap or the alternative path of 25/50/100 Gb. Avago, having acquired Broadcom and Emulex, seems to be the lead cheerleader behind the latter, though QLogic and Mellanox are also pushing it. And of course everyone is acting very friendly in public, knowing that customer adoption will ultimately drive which standard is adopted.
So far, 100 Gb Ethernet is touted as an inter-switch link, while 40 Gb or 25/50 Gb Ethernet is the focus for server interconnects. Available PCI Express bandwidth is one reason for this segmentation, since it is very difficult for any server to saturate a 100 Gb link. But PCIe Gen 4 will double per-lane throughput, opening the door to 100 Gb servers sooner rather than later. And the challenge of InfiniBand, already pushing past 50 Gb, means greater interest in 100 Gb Ethernet in high-performance computing.
The question comes down to the two roadmaps for speed between 10 Gb and 100 Gb: Do you hold out for (potentially more expensive) 40 Gb or jump on 25/50 Gb? Are you with Intel or the other chipmakers? What kind of cabling do you have or prefer?
Less Than Ten, More Than One
Many servers and network devices need more than 1 Gb of throughput but don’t want or need 10 Gb and the potential expense of fiber optic connections. That’s where NBASE-T comes in. This new standard would allow 2.5 Gb or 5 Gb Ethernet over existing copper cabling. Although the NIC and switch would need to be changed, NBASE-T has wonderful potential beyond the datacenter to provide more performance with little additional investment.
This is especially true for Wi-Fi access points, which might need more than 1 Gb of backhaul but have to make do with existing cabling. The next generation of Cisco AP’s and campus switches will likely support NBASE-T out of the box and customers will see much improved performance. Another benefit of NBASE-T is Power over Ethernet: Wi-Fi AP’s need PoE but power requires copper, making fiber-based 10 Gb Ethernet use even more difficult.
NBASE-T is a compromise between the hardware vendors, with the Intel side seeming to win out. It’s essentially 10 Gb Ethernet “slowed down” for 2.5 and 5 Gbps rather than a totally new standard. And it can run at 1 Gb too, an intriguing possibility as an alternative to today’s aged 1000BASE-T.
Here’s a great presentation on NBASE-T from Cisco at Tech Field Day
Ideally, future Ethernet chips would automatically detect all these speed combinations and negotiate the best-possible performance for any given connection. Indeed, it’s nice to see the IEEE talking about 2.5 and 5 in the same breath with 10, 25, and 40. But this isn’t a reality today. Buyers have to make a choice and ensure that both ends of the wire support whichever speed they select.
Stephen’s Stance
“One size fits all” doesn’t work for Ethernet, but this proliferation of speed options sounds like trouble without automatic capability negotiation. It’s nice to have options, but the IEEE must remain focused on interoperability and rein in the interests of the various companies proposing next-generation Ethernet technologies.

Agreed Ethernet ends up with more link and physical layer variants than any one application needs…and many times several alternatives compete (particularly in the standards process) for a given role. But Ethernet for the data center is not as chaotic as presented here!
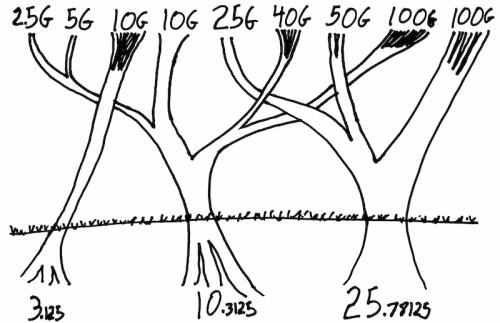
First, we have an evolution of the speed of a single serial connection on the NIC or switch ASIC (the “serdes”). These are the three roots shown in the trees picture. The 3Gb serdes was the workhorse a decade ago. The 10Gb serdes came into use 7 years ago, and is very much the data center mainstream today. The 25Gb serdes comes into use this year and will replace 10Gb as mainstream over the next few years.
Second, at a given point in time (a given serdes speed) one chooses speed and cost by choosing a number of serdes. This is typically 1 serdes for a basic connection, 4 serdes for a fast connection, and a few applications will use 8/10/12/16 for really fast connections.
Third, this is not about ASIC and device vendors. Yes, one vendor may be a little earlier to the party than another and make noise about that, but everyone in the industry is using roughly the same serdes designs. In the end, over the last 7 years everyone did 10GbE (typically to an SFP+ connector) with one serdes, and 40GbE (typically to a QSFP connector) with four serdes. 100GbE (10 serdes) was available for switch-to-switch and telco, but as you say PCIe 3 isn’t fast enough to support 100GbE NICs, so 10×10 100GbE never got cost effective enough to mainstream in the data center.
It has been obvious for several years that as 25Gb serdes mainstream this year, we will see the 4-serdes 100GbE (4×25), probably in a QSFP28 connector, mainstream in the data center, with less expensive 25GbE (1×25) as the server-to-edge-switch connection coming into use over time.
If you look at the emerging 400GbE work in the standards committee, it started as 16 serdes of 25Gb/s — very similar to 100GbE as 10 serdes of 10Gb/s almost a decade before. While alternatives are very much still being debated, 400GbE may evolve to 8 serdes of 50Gb/s, and sometime in the next decade to 4 serdes of 100Gb/s, which is the first time I expect to see 400GbE deployed in any volume in the data center.
Which is just history repeating itself. This really is, at its root, an orderly evolution.
The rest is variants, whether trying to force very high speed signals onto classic unshielded twisted pair Ethernet cables (turned out to require design heroics even at 10Gb/s), across chassis switch backplanes, into automotive applications, into campus applications like cabling to wireless APs which require PoE, over optics in Metro Ethernet rings, into the EPON world, and many other uses of Ethernet which don’t come to the typical user’s mind.
@FStevenChalmers
Can I just quote this comment and use it as a new blog post?
(you’re absolutely correct about everything as far as I can tell!)
To further the thought over the years Ethernet has also eliminated most other comm channels with broader use cases come the need for more variants like NBASE-T for fast access points over twisted pair with POE but we aren’t discarding the slow channel versions (1Gbase-T ports almost always still support 10Mbps).
One minor correction/addition to the vendor mix. While Avago did buy Broadcom Qlogic bought Broadcom’s Ethernet adapter chip business earlier. That leaves Avago (Emulex), Intel and Qlogic (Broadcom) as the volume LOM chip vendors.
Thank you! Not sure it stands alone without a lot of qualification. Feel free to quote me on your blog, just attribute to me as an individual, since I’m not speaking for HP.
What I did was filter what’s happening in Ethernet through the eyes of a mainstream, cost effective but reasonably leading edge data center.
If this was written for a telco or service provider audience — which I’m far less qualified to address — the high serdes count connections are far more useful, far sooner (all those serdes just go a few inches to an expensive telco optical module which stuffs all those bits onto a single mode fiber anyhow).
Likewise if it were written for the campus, there would have been emphasis on the 2.5GbE or 5GbE over unshielded twisted pair, with PoE, for connecting 802.11ac access points. The 3 or 5 meter twinax DAC cables we use for server to ToR in the data center just don’t have the reach campus needs, and the optical connections we use from ToR to spine/aggregation tend to be too expensive to connect a single access point and can’t carry PoE.
@FStevenChalmers
(speaking for self, works in HP Networking, which competes in these spaces)
Thx for the Post, i have been looking everywhere for an answer, if NBase-T uses some new 2.5Gb SerDes.
But if NBase-T is basically a slower 10Gbps, how are they going to bring the cost down? After All 10Gbps has been available for many years and its prices is still out of reach for most consumers.
Excellent discussion ! Apropos , you need a a form , my family filled a template form here
http://goo.gl/OToRa0